" height="40.0000004693602px" id="JNsUwfViG" width="56px"/></svg>)
[
]
What Are Enterprise AI IDEs?
Why enterprises need AI IDEs that add execution boundaries, workspace isolation and keep every AI run traceable to scale safely
Cloud IDEs & Environments
Traditional IDEs fail because they assume software is deterministic, whereas AI behavior is dictated by shifting prompt states and opaque model versions. Scaling requires moving beyond "editing files" to managing a unified execution runtime where every model call is a traceable event.
Most teams treat prompts as static strings, leading to "prompt sprawl" in which logic diverges across services without a shared lineage. Enterprise IDEs solve this by turning prompts into executable units with strict schemas, ensuring you can precisely reconstruct which input triggered a production failure.
Security is often misplaced at the model API level, leaving the data preprocessing and retrieval stages exposed in shared memory. True isolation demands a boundary that encapsulates the entire pipeline, from the moment raw data is loaded to the final output storage, preventing leakage across team workspaces.
Allowing teams to direct-call various LLM providers creates a nightmare for cost tracking, compliance, and consistent fallback logic. A centralized gateway acts as a strategic control point, enforcing model capabilities against organizational policy rather than allowing engineers to embed provider-specific code.
In regulated sectors, "it worked on my machine" is a liability; you must be able to prove how a specific AI decision was reached. By recording execution metadata, including data snapshots and intermediate transforms, teams transition from guesswork to deterministic replays of past AI behaviors.
Hardening AI workflows with isolation and policy checks introduces unavoidable latency and restricts traditional debugging methods. The master strategy is to classify workloads: use flexible environments for rapid prototyping, but mandate the controlled execution layer for anything touching sensitive data or production traffic.
Introduction
AI development inside companies has moved past notebooks and one-off scripts. Teams now build internal copilots, data pipelines, and decision systems that rely on language models trained on private data.
According to Gartner, over 70 percent of enterprises are expected to operationalize AI workloads by 2026. A separate Statista estimate shows enterprise AI adoption crossing 35 percent globally, with the fastest growth in internal automation and decision systems. These numbers point to scale, not maturity.
On Reddit, threads in r/ExperiencedDevs and r/AI_Agents repeat the same complaint. Teams can build working models, but cannot explain how prompts evolve, who changed them, or why outputs differ between environments.
The problem is how AI systems behave once multiple teams share them. This article breaks down how enterprise AI IDEs address that gap, where scaling fails in real systems, and how ORGN enforces execution boundaries rather than relying on process discipline.
The Shift from Local AI Experiments to Shared Systems
Early AI workflows feel simple. A developer writes a script, calls a model API, and gets useful output. That simplicity disappears once more, as engineers and services depend on the same workflow.
From notebooks to multi-user environments
Single-user workflows rely on tools like Jupyter Notebook or local Python scripts. Prompts live inside code, datasets sit on local machines, and outputs are inspected manually.
A typical early-stage workflow looks like this:
from openai import OpenAI |
No versioning exists for the prompt beyond Git history. No record exists of which dataset version was used. The runtime environment is implicit and often tied to a single machine.
As soon as a second team reuses the same logic, divergence starts. One team tweaks the prompt. Another swaps the model. A third adds preprocessing. None of these changes is tracked as part of a unified execution system.
At this stage, reproducibility breaks. Given an output, no one can reconstruct the exact input, model configuration, or intermediate steps that produced it.
Why “just use VS Code” stops working
Tools like Visual Studio Code manage source code well. They track file changes, support debugging, and integrate with version control systems.
AI workflows introduce a state that does not live in code:
Prompt templates change outside version control through experimentation
Model selection depends on runtime configuration or API routing
Intermediate steps, such as embeddings or retrieval, are not visible in a single file
Consider a retrieval-augmented pipeline:
docs = vector_db.search(query) |
The actual behavior depends on:
The state of the vector database
The ranking algorithm used during retrieval
The model version behind llm.generate
Hidden retries or fallbacks in the API layer
None of these are captured by the IDE; The code shows intent, not execution. Once teams scale, debugging turns into guesswork. Two identical codebases can produce different outputs because runtime dependencies differ. Traditional IDEs assume determinism from code. AI systems break that assumption because execution depends on external systems and mutable data.
What an Enterprise AI IDE Is
At this point, the idea of an IDE shifts. It is no longer about editing code. It becomes about controlling how AI workflows execute across teams and environments.
Not a UI layer, but an execution system
An enterprise AI IDE defines the runtime in which prompts execute, models are selected, and outputs are handled. The interface is secondary. The execution model is the real system.
At this stage, the IDE stops being a text editor and starts behaving like an execution surface. Prompts are not written in isolation; they are tied to a workspace, a model, and a controlled runtime.
The interface reflects this shift. Prompt execution, model selection, and workspace context are visible as first-class elements rather than hidden within code or configuration files.
In a controlled AI IDE, a prompt is not just a string. It is an executable unit tied to:
A specific model version
A defined input schema
Access policies for data sources
Logging and retention rules
Execution becomes explicit. Every run is traceable.
Core components that change the definition
An enterprise AI IDE introduces components that do not exist in traditional tools. A prompt execution engine manages how prompts are compiled, parameterized, and executed against models. It tracks versions and enforces consistency.
Model routing and access control determine which models can be used, under what conditions, and by which teams. Instead of direct API calls, requests pass through a controlled layer. Workspace isolation separates environments across teams. Data, prompts, and outputs remain scoped to a workspace, preventing accidental leakage.
Output handling defines what happens after execution. Logs, traces, and results follow predefined policies instead of ad hoc storage. These components shift the system from development tooling to execution infrastructure. Code becomes one input among many, not the single source of truth.
Where Scaling Breaks First
Small teams can tolerate inconsistency. Once AI workflows spread across services and teams, hidden state and uncontrolled variation start causing production issues that are hard to trace.
Prompt sprawl and lack of versioning
Prompts rarely stay static. Engineers tweak wording, add guardrails, or inject new context based on observed failures. These edits often happen directly inside services, not in a shared system.
A typical pattern looks harmless:
PROMPT = """ |
Another team copies the same logic and modifies the tone or structure. A third team adds a few short examples. Over time, the same logical task exists in multiple forms with no shared lineage. Production issues follow a familiar shape. Support escalations mention inconsistent responses. Engineers compare code and see only minor differences. The real issue sits in prompt drift, not in application logic.
Without prompt versioning tied to execution, there is no way to answer a basic question. Which exact prompt produced this output in production last Tuesday?
Model fragmentation across teams
Different teams choose different models based on cost, latency, or perceived quality. Some call hosted APIs. Others deploy open models internally. A few mix both, depending on the endpoint.
A single service can end up with conditional routing:
def generate(prompt, priority): |
Now multiply that across teams. Each service defines its own routing logic, fallback behavior, and retry strategy.
Security and compliance break at this layer. One team may send sensitive data to an external provider while another keeps everything internal. Audit teams cannot reason about data flow because there is no central control point. Cost tracking also becomes noisy. Billing spreads across providers and accounts, making it difficult to attribute usage to specific workflows.
Hidden state in pipelines
AI pipelines are rarely single-step operations. They include retrieval, preprocessing, enrichment, and post-processing. Each stage introduces a state that is not visible in the final code path.
A simplified pipeline:
context = retrieve(query) |
The actual execution includes more:
Retrieval depends on index freshness and ranking logic
Sanitization may remove or alter content based on rules
Model calls may include retries or fallback providers
Storage may trigger downstream workflows
When an output looks incorrect, engineers inspect the final prompt. The issue often originates earlier in the pipeline. Without a system that records each stage of execution, debugging becomes a matter of reconstructing the execution. Teams rely on logs that were never designed to capture full context.
Execution Boundaries: The Missing Layer
The scaling problems above share a common root. There is no defined boundary for the control, observation, and enforcement of execution.
Why AI IDEs need runtime isolation
Traditional systems separate development and execution. Code is written locally and then deployed to controlled environments. Observability and policy enforcement happen at runtime.
AI workflows collapse that separation. Prompts execute directly against models, often from within application code. There is no distinct runtime layer where policies can be enforced consistently.
Without a boundary, every service becomes its own execution environment. Each team decides how prompts run, how data is handled, and how results are logged. An enterprise AI IDE introduces a single execution layer. All prompts pass through it, regardless of their origin. Control moves from the application code to the execution system.
Memory visibility and data exposure
AI workloads process sensitive data in memory. Prompts often include internal documents, user data, or operational logs. Outputs may contain derived insights that should not leak.
In a typical hosted setup, the flow looks like this:
response = external_llm.generate(prompt) |
The prompt is decrypted and processed inside infrastructure that the enterprise does not control. Even with contractual guarantees, runtime visibility remains unclear. The risk is not limited to storage. Memory during execution is exposed to the host system, debugging tools, and shared infrastructure layers.
Execution boundaries address this by defining where data is visible. If prompts and intermediate states run inside controlled environments, exposure is limited to that boundary. The problem shifts from “who promises not to look” to “who can technically access memory during execution.”
ORGN’s Approach: IDE as a Controlled Execution Environment
ORGN treats the AI IDE as an entry point into a governed execution layer. The focus is not on the editing experience but on how every workflow is run, observed, and restricted.
AI IDE backed by secure runtime
In ORGN, prompt execution does not happen inside arbitrary application code. It runs inside isolated environments managed by the platform.
Each execution carries context:
Prompt version
Model selection
Input data references
Execution policies
Execution is not treated as a black box. Each run carries metadata that defines how and where it was executed, enabling debugging and auditing without reconstructing state from logs.
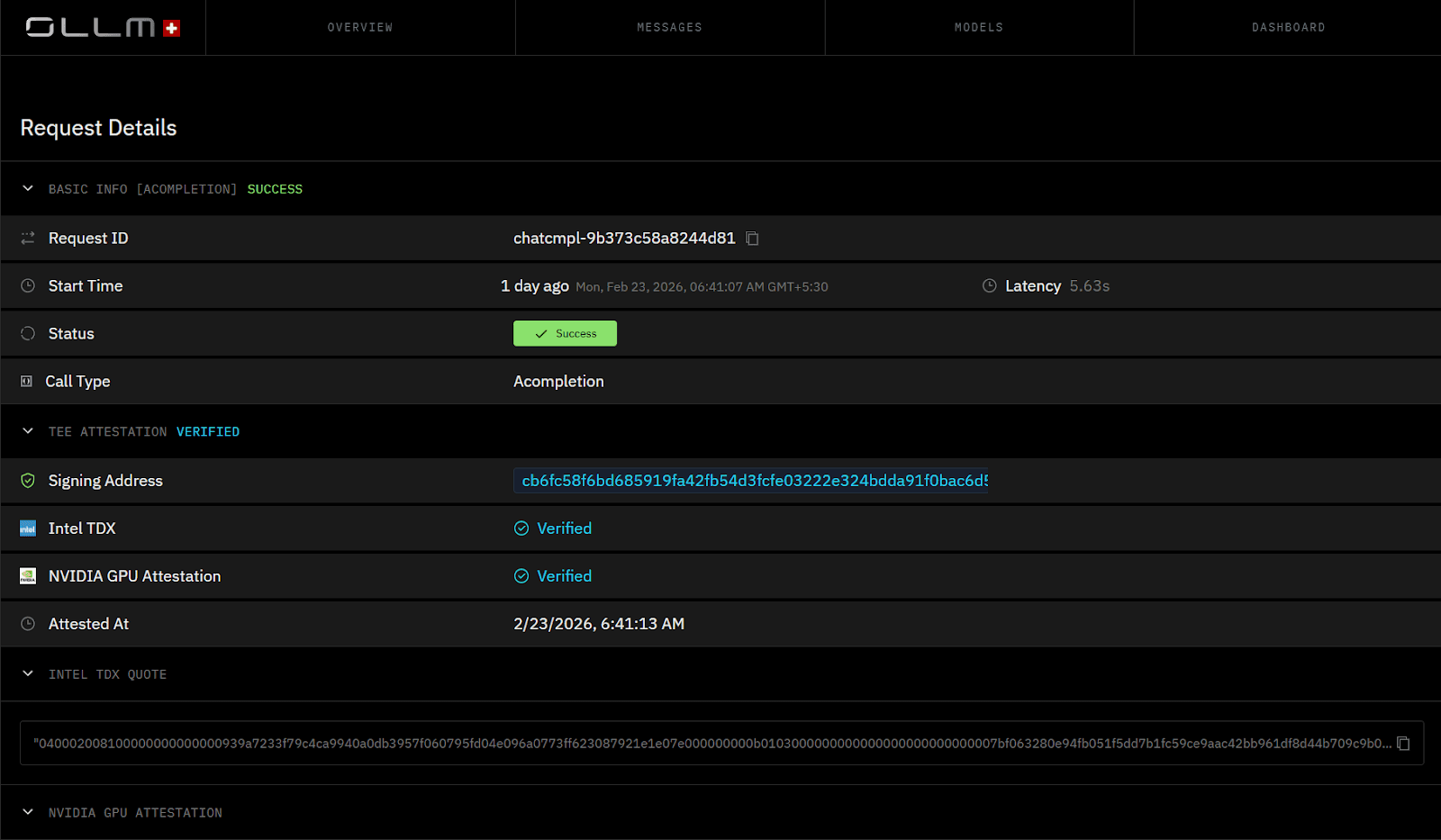
The platform exposes execution details directly, including model selection, input structure, and runtime context, rather than leaving them implicit in application code.
Instead of embedding logic like llm.generate directly in services, requests go through a controlled interface.
# Within an ORGN workspace, the agent receives the task, model context, and execution policies as part of the governed runtime, not as application-level configuration. |
The difference from a standard model call is not the interface; it is where execution happens and how it is governed. The platform enforces isolation, tracks execution metadata, and applies policies before and after the model runs, all within the controlled workspace rather than inside application code.
Unified gateway for model access
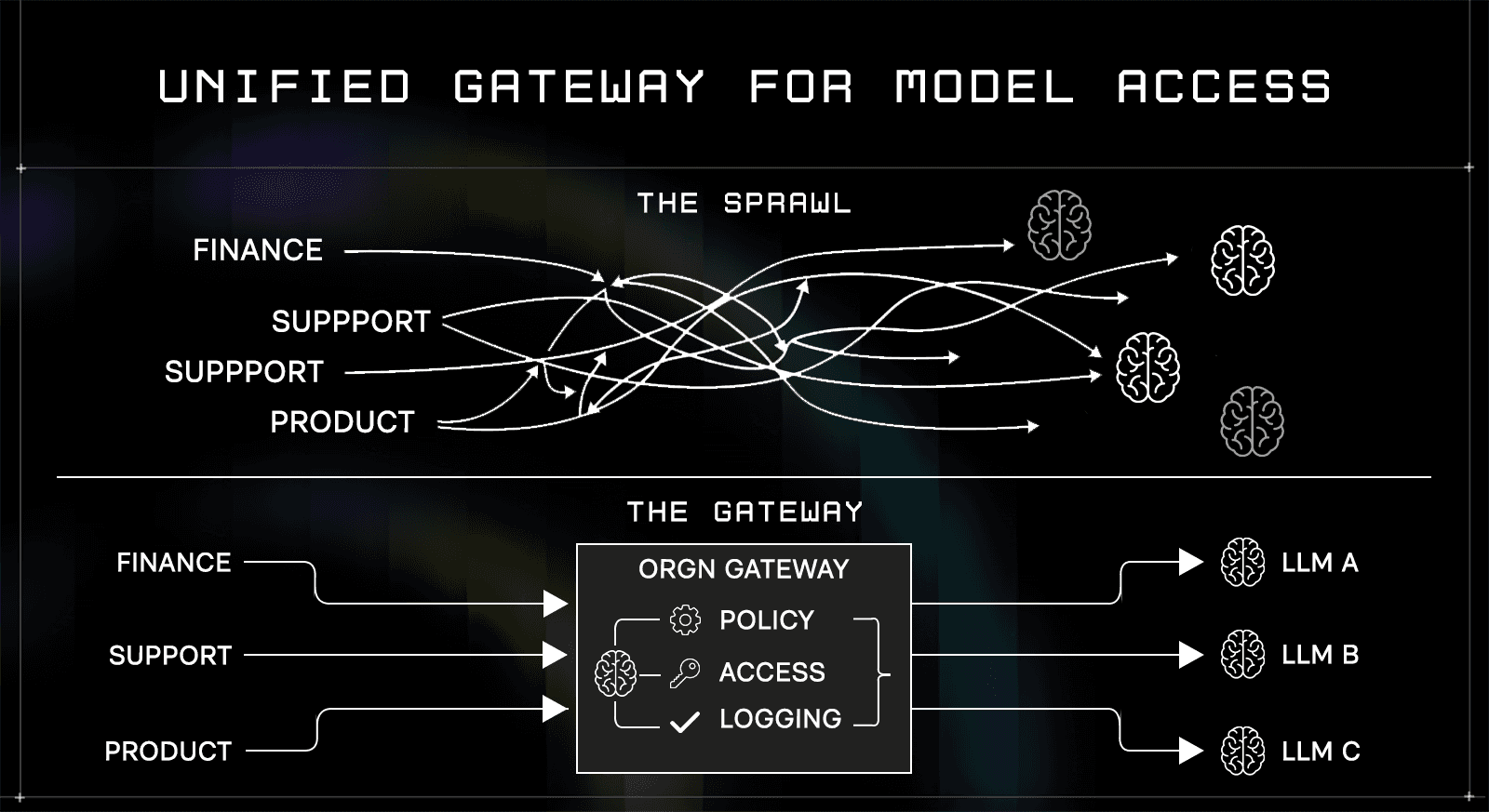
Instead of allowing direct access to multiple model providers, ORGN introduces a single gateway. All model interactions pass through this layer.
The gateway handles:
Model selection based on policy
Access control per workspace or team
Routing between internal and external models
Consistent logging and tracing
Teams no longer embed provider-specific logic in their code. They request capabilities, and the gateway resolves how those capabilities are fulfilled. This removes fragmentation. Security teams gain a single point where policies can be enforced. Platform teams gain visibility into usage across the organization.
Execution as a first-class concept
ORGN treats each AI operation as a structured execution event. It is not just a function call returning text.
An execution includes:
Inputs, including prompts and data references
Model and configuration used
Intermediate steps if the workflow spans multiple stages
Outputs and any side effects
This structure enables reproducibility; Given an execution record, teams can replay or audit the workflow. It also enables enforcement. Policies can be applied at execution time, not just during development.
Workspace-Level Isolation, Not Just Prompt-Level Control
Prompt-level control fixes only the last step of the pipeline. Most data exposure and inconsistency happen before and after the model call.
Why prompt-level security is insufficient
Teams often secure the model invocation and assume the system is safe. The rest of the pipeline still runs in shared infrastructure.
Consider a common pattern:
data = load_internal_data() |
If only llm.generate runs in a controlled environment, load_internal_data and filter_sensitive still execute in plain memory. Sensitive data is exposed before the model call even begins. Logging systems add another layer of exposure. Debug logs often capture intermediate data for troubleshooting. These logs persist outside any controlled boundary. The result is partial protection. The most sensitive stages of the pipeline remain unguarded.
Full workspace execution model
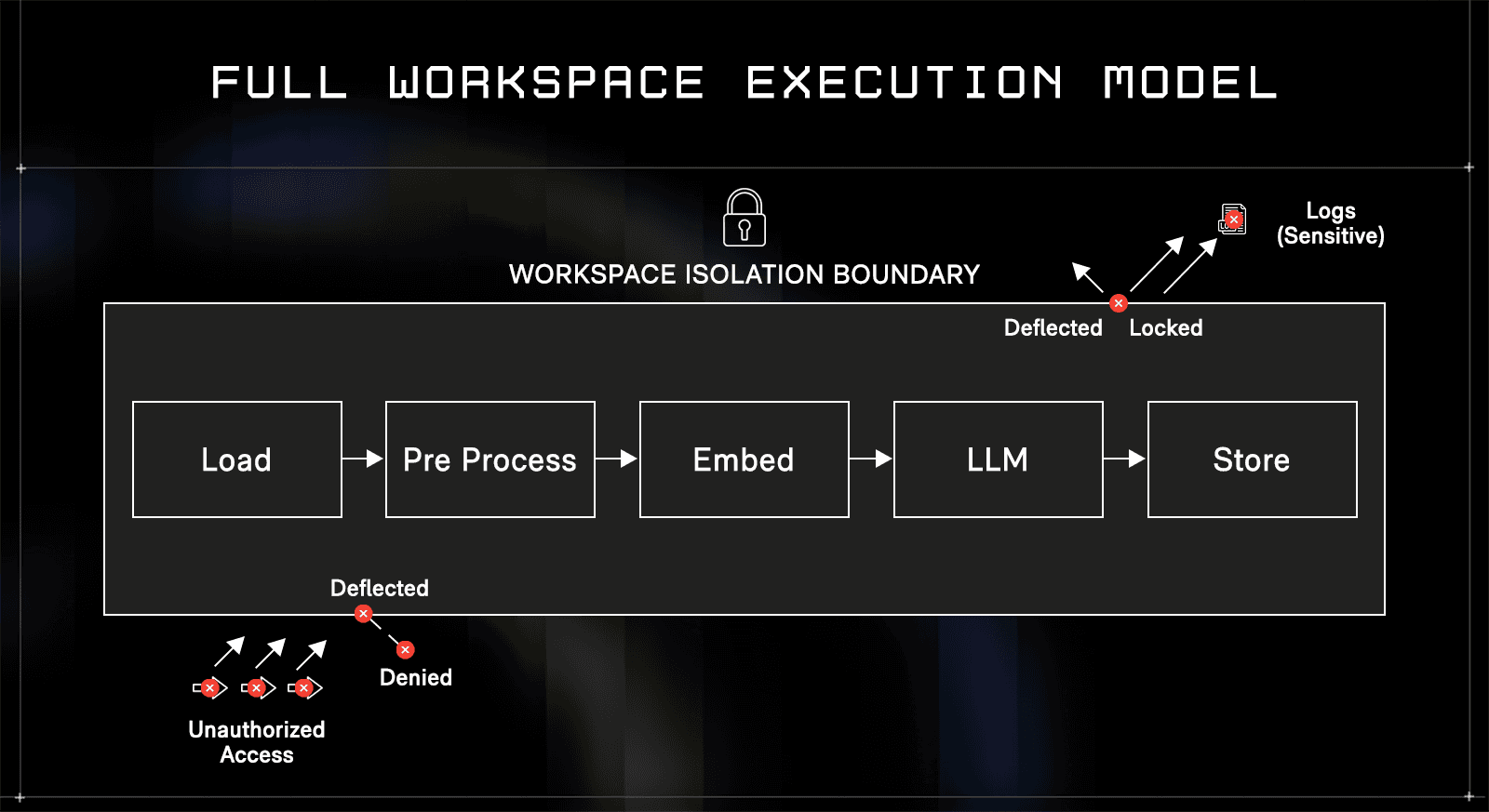
ORGN extends control to the entire workflow. Each step, from data loading to output storage, runs inside the same isolated environment.
Isolation is applied at the workspace level, not just at the model call. Every stage of the pipeline executes within the same boundary, eliminating gaps among preprocessing, inference, and storage.
Each workspace defines its own execution scope, including accessible data, allowed models, and runtime policies, preventing overlap between teams even when they share infrastructure.
A workflow becomes a single execution unit:
When a project is created in ORGN, the repository is cloned and deployed on an isolated branch. This means teams work entirely within that isolated environment, and any changes only reach the main repository and main branch after explicit human review and approval. Nothing merges without a deliberate promotion step, giving teams a structural guarantee that AI-generated changes cannot reach production unreviewed.
def workflow(query): |
All functions execute within a controlled workspace. Memory is not shared with external systems. Intermediate states do not leak into logs or host-level monitoring tools. Isolation at this level removes gaps between steps. Teams no longer need to reason about which parts of the pipeline are safe.
Isolation across teams and services
Multiple teams can run workflows on the same platform without sharing state. Each workspace maintains its own data scope, execution policies, and model access rules. A finance team and a support team may use the same underlying models. Their data, prompts, and outputs remain separated.
This separation is enforced at execution time, not just through naming conventions or access controls in code.
Versioning, Reproducibility, and Auditability
AI systems fail in ways that are hard to trace. Outputs change without obvious code changes. Reproducing past behavior becomes a manual investigation.
Reconstructing outputs
In enterprise environments, teams must answer a simple question during incidents. What produced this output? Traditional logging captures inputs and outputs. It rarely captures the full execution context.
An AI execution requires more detail:
Exact prompt version
Model version and configuration
Input data snapshot or reference
Intermediate transformations
Without these, reproduction is guesswork.
In ORGN, each execution is recorded as a structured event. Re-running an execution uses the same prompt, model, and parameters.
# Each execution in ORGN is recorded as a |
Review is not a best-effort reconstruction from scattered logs. Every session preserves the prompt, model selection, file diffs, and agent reasoning chain as a structured record that can be inspected directly within the ORGN project.
Deterministic execution constraints
Language models introduce non-determinism through sampling. Even with identical inputs, outputs can vary.
Enterprise systems reduce this variability by enforcing constraints:
Controlled prompt templates
Stable model versions
ORGN supports model selection at the project level, with a default model set per project and the option to override for individual requests. Teams can standardize on a specific model for production workflows while allowing experimentation in isolated worktrees. Determinism is not absolute; it is bounded. The goal is to reduce variation enough that debugging remains practical.
Audit trails and compliance
Regulated environments require traceability. Financial and healthcare systems must show how decisions are made. AI systems complicate this requirement. Outputs are generated rather than explicitly programmed.
Audit trails must include:
Data sources used during execution
Transformations applied
Model decisions and outputs
ORGN records execution traces that map inputs to outputs through each stage. Compliance teams can inspect these traces without relying on developer memory or incomplete logs. For teams using confidential models deployed on TEEs via the OLLM gateway, cryptographic attestation records are generated for each inference session. These records verify enclave identity, runtime integrity, and that the expected code executed inside a verified environment, providing cryptographic proof of how a specific AI decision was reached, not just a log entry.
Multi-Team Collaboration Without Cross-Contamination
Scaling AI inside an organization introduces coordination problems. Teams share infrastructure but must not share data or execution context.
Tenant isolation inside shared infrastructure
A single platform may serve dozens of teams. Each team runs workflows that process sensitive data.
Isolation must prevent:
Data leakage across teams
Accidental access to prompts or outputs
Shared caches exposing intermediate results
In ORGN, isolation is enforced across a four-level hierarchy, and it is worth being precise about what each level means.
Teams are the top-level unit. A team defines who has access to the environment, its members, cloned repositories, data, prompts, and outputs. Access is scoped at this level, so only members of a team can interact with resources that belong to it.
Projects live inside teams. A team can have multiple projects, each tied to a specific repository or part of a repository. This lets a single team work across multiple codebases simultaneously without mixing context. Each project is deployed on its own isolated project workspace.
Tasks live inside projects. Tasks are either AI-generated from repository analysis or created manually. They represent discrete units of work with their own lifecycle states, priority, and assignees.
Worktrees are created when a task moves into active execution. Each worktree is an isolated coding environment deployed inside a TDX-encrypted sandbox. Memory is encrypted at the hardware level, and the worktree is scoped entirely to that task; it does not share state with other worktrees, other projects, or other teams, even when running on shared underlying infrastructure.
Two teams can run identical workflows against different data, and the results remain fully isolated, because enforcement happens at execution time across all four levels, not through naming conventions or access controls in application code.
Policy enforcement at execution time
Access control defined in code is easy to bypass. Engineers may introduce new services, scripts, or integrations that skip existing checks. ORGN enforces policies when execution happens. Every request is evaluated against workspace rules before it runs.
Policies can include:
Which models are allowed
Which data sources can be accessed
Whether outputs can be stored or exported
Enforcement at runtime ensures that even ad hoc workflows follow the same rules.
Collaboration without shared state
Teams often need to collaborate on workflows without exposing raw data. ORGN supports this by separating workflow definitions from data access. A team can share a workflow template without sharing the underlying dataset.
For example:
def shared_workflow(input_data): |
Another team can reuse the workflow with its own data inside its workspace. The logic is shared, the data is not. This allows reuse without cross-contamination.
Performance and Practical Constraints
Isolation and controlled execution introduce overhead. Teams need to understand where the cost shows up and when it is justified.
Overhead of isolated execution
Running workflows inside controlled environments adds latency. Memory protection, restricted I/O, and policy checks increase execution time compared to direct API calls.
A simple comparison helps:
# Direct call |
The second path includes the setup of validation, routing, and isolation. Each step adds milliseconds or more, depending on workload complexity. For high-frequency, low-sensitivity tasks, this overhead can become noticeable. Batch processing and caching strategies often compensate, but they require deliberate design.
Large models introduce additional constraints. Some environments limit memory or require partitioning workloads across nodes. This affects throughput and concurrency.
Debugging limitations
Controlled environments restrict direct inspection. Engineers cannot attach debuggers to inspect memory or intermediate states freely.
Debugging shifts toward structured traces and controlled logging. Instead of inspecting live state, engineers analyze recorded execution data. This requires a change in workflow. Teams must design observability into the system from the start.
When not to use full isolation
Not every workflow needs strict control. Internal experimentation, non-sensitive data processing, and early prototyping can take place in less restrictive environments.
Applying full isolation everywhere slows development. Teams should classify workloads based on data sensitivity and compliance requirements.
A common split:
Experimental workflows in flexible environments
Production workflows in controlled execution systems
This balance keeps development practical while protecting critical paths.
Comparison: Traditional AI Tooling vs Enterprise AI IDEs
The difference between traditional setups and enterprise AI IDEs lies in where control is enforced.
Traditional approach
Teams build AI features directly inside application code. Model calls are embedded in services. Each team manages its own prompts, configurations, and integrations.
Execution flow:
response = provider.generate(prompt) |
Characteristics:
Decentralized model access
No unified prompt management
Logging handled per service
Limited visibility across teams
This approach works at a small scale. As systems grow, inconsistencies and security gaps appear.
Enterprise AI IDE model (ORGN)
Execution moves out of the application code into a controlled layer. Services request execution instead of directly calling models.
Execution flow:
response = orgn.execute( |
Characteristics:
Centralized execution control
Unified model access through a gateway
Workspace-level isolation
Structured execution records
The shift is architectural. Control moves from distributed services into a single execution system.
Narrative comparison
In traditional systems, each service behaves like its own mini platform. Teams solve the same problems repeatedly, often with slight variations.
In an enterprise AI IDE, the platform handles execution concerns once. Teams focus on defining workflows rather than managing infrastructure details. The trade-off is flexibility versus control. Traditional setups allow quick changes but introduce inconsistency. Controlled systems enforce consistency but require upfront structure.
Where This Matters in Real Systems
Certain use cases require controlled execution. In these environments, trust cannot rely on convention or documentation.
Internal copilots trained on company data
Enterprises build copilots that access internal documents, logs, and knowledge bases.
A typical flow:
docs = internal_search(query) |
Without controlled execution, sensitive information can leak through logs, caching layers, or external providers.
Isolation ensures that data remains within defined boundaries during processing.
Regulated environments
Financial systems process transactions, reports, and compliance data. Healthcare systems handle patient records.
Regulations require traceability; Teams must show how outputs are generated and which data was used. Execution records and audit trails become mandatory, not optional.
Multi-tenant SaaS platforms
SaaS platforms process data from multiple customers. AI features such as summarization or recommendation operate on this data.
A failure in isolation can expose one customer’s data to another. Even indirect exposure through shared caches or logs is unacceptable. Controlled execution ensures that each tenant’s workflows remain isolated.
Conclusion
Enterprise AI systems fail in predictable ways once multiple teams, shared data, and external models come into play. Prompts drift, model usage fragments, and pipelines carry hidden states that no one can fully trace. Teams end up debugging outputs without knowing which input, model version, or intermediate step produced them. Control is spread across services, and consistency depends on discipline rather than enforcement.
The article examined how enterprise AI IDEs address these issues by shifting control into a governed execution layer, where workflows run with versioning, isolation, and auditability built in. ORGN applies this model across prompt execution, workspace-level isolation, and centralized model access, turning AI development from a scattered set of scripts into a system where every run is controlled, observable, and reproducible.
FAQs
1. What is an enterprise AI IDE?
An enterprise AI IDE is a controlled environment in which AI workflows execute under defined policies, model access rules, and traceable outputs.
2. How is it different from a traditional IDE?
Traditional IDEs focus on writing code. Enterprise AI IDEs control execution, data handling, and model interaction.
3. Why do AI systems need execution isolation?
AI workflows process sensitive data in memory. Isolation limits exposure during execution and prevents leakage across systems.
4. What problems do enterprise AI IDEs solve?
They address prompt versioning, model access control, reproducibility, and data isolation across teams.