" height="40.0000004693602px" id="JNsUwfViG" width="56px"/></svg>)
[
]
AI Software Development:
See how AI agents now plan, code, test, and ship software end‑to‑end, and how ORGN, Devin, and Coder fit different teams and risk profiles
AI Development Tools
AI boosts coding 55% faster with 40% better quality via ORGN (unified context + TEE security), Devin (VM autonomy), Coder (governed infra)
ORGN security leader: Intel TDX TEEs + cryptographic attestation via OLLM solve fragmentation/compliance for privacy-conscious devs, fintech, healthcare, defense
Devin solo powerhouse: Instant GitHub to PR autonomy, no setup to replace junior devs
Coder team governance: self-hosted infra + agent boundaries, Kubernetes expertise required/no managed cloud
Match needs: ORGN (compliance + security), Devin (speed), Coder (coordination)
AI Software Development: How AI Automates the Coding Lifecycle
Software is eating the world, and AI is now eating software development. What once took a team of engineers weeks to build, test, and ship can now be initiated with a single natural language prompt. The tools handling this aren't just smarter autocomplete; they're autonomous agents that plan, write, debug, and deploy code end-to-end. For engineering teams, this isn't a future trend to watch; it's a present reality to adapt to.
This article breaks down what AI software development actually means, where it fits in the dev lifecycle, and how the three leading tools, ORGN, Devin, and Coder, approach it differently. By the end, you'll have a clear picture of how each tool works, where each one falls short, and how to choose the right one for your team's specific situation.
What is AI Software Development?
AI software development integrates artificial intelligence to automate and enhance every phase of the software development lifecycle, from requirements gathering and code generation to testing, deployment, and maintenance. It uses large language models (LLMs), autonomous agents, and intelligent tools to handle repetitive tasks while amplifying developer productivity and code quality.
Core Components
Automation: Generates code, tests, and documentation from natural language prompts:
Code: Tell the AI to "Add JWT refresh token rotation to our existing auth middleware, invalidate old tokens on use" and it generates the full middleware update with token blacklisting logic, Redis TTL handling, and the correct error responses, adapted to your existing code structure.
Tests: Ask it to "Write integration tests for the Stripe webhook handler, cover failed payments, refunds, and duplicate events" and it produces tests with mocked Stripe payloads, idempotency checks, and database state assertions already wired up.
Documentation: Prompt it to "Document the rate limiter we built for the public API" and it generates endpoint-level docs covering rate limit headers, retry-after behavior, and example 429 responses, pulled directly from the actual implementation.
Intelligence: Predicts bugs, optimizes performance, and suggests architecture improvements:
Bug Prediction: Spots an unhandled promise rejection inside an async database call in an Express route and flags it before it silently swallows errors in production.
Performance: Detects N+1 queries in a REST endpoint loading user posts with comments and suggests eager loading with a single JOIN query, cutting database round-trips from 50 down to 1.
Architecture: Reviews a monolith where the notification service is tightly coupled to the user service and recommends extracting it behind an event queue like SQS or Kafka, so notification failures stop blocking user operations entirely.
Collaboration: Provides persistent context across tools, reducing fragmentation:
Persistent Context: A bug filed in GitHub Issues gets traced through the codebase automatically. The AI identifies the failing edge case in the payment retry logic and opens a PR with a fix and a regression test, without a developer having to manually connect the dots.
Team Sync: After a large refactor, ask the AI to summarize what changed for the QA team, and it produces a plain-English breakdown of which endpoints changed, what the risk surface looks like, and what needs testing.
Cross-Tool: A Jira ticket for "add two-factor authentication" triggers the AI to create the feature branch, scaffold the TOTP implementation, write unit tests, and link everything back to the original ticket, preserving full context.
The Five Stages AI Has Taken Over in the Dev Lifecycle

Modern software development isn't a single act; it's a pipeline of distinct stages, each with its own complexity and overhead. AI has carved out a meaningful role in each of them. Here's where it's making the biggest difference:
1. Code Generation & Completion
Code generation is where most developers first encounter AI. LLMs analyze your codebase, understand the patterns and conventions you're already using, and generate entire functions, components, or modules from a natural language prompt. Type "implement rate limiting middleware for an Express API using Redis" and get back production-ready code, imports, error handling, and edge cases included. This isn't generic boilerplate; modern tools adapt to your specific stack and style.
2. Debugging & Vulnerability Detection
AI excels at catching problems before they reach production. Rather than waiting for a test to fail or a user to report an error, AI tools scan code in real time, flagging logic errors, potential runtime failures, and security vulnerabilities like SQL injection or exposed secrets as you write. In regulated environments like fintech or healthcare, this layer of early detection is particularly valuable.
3. Test Generation
Writing tests is one of the most consistently skipped steps in fast-moving teams. AI closes that gap by automatically generating unit, integration, and edge-case tests, tied directly to the code being written or changed. The better tools don't just generate tests; they run them in isolated environments and iterate until they pass, giving you coverage without the manual overhead.
4. Code Review & Documentation
AI brings consistency to code review, catching style violations, enforcing standards, flagging performance issues like O(n²) loops, and suggesting refactors across large codebases where human reviewers lose focus. On the documentation side, it generates JSDoc, API references, and inline comments in real time, keeping documentation current rather than becoming an afterthought.
5. CI/CD & Deployment Automation
At the furthest end of the lifecycle, AI agents can orchestrate the entire path from a merged PR to a deployed service. This includes running pipelines, catching failed builds, auto-generating deployment summaries, and triggering rollbacks when something goes wrong. For teams managing microservices across multiple repos, this removes significant manual coordination overhead.
Why Most AI Coding Tools Still Fall Short for Enterprise Teams
AI coding tools have made individual developers significantly faster. But when enterprise teams, particularly those in regulated industries like fintech, healthcare, or defense, try to adopt them at scale, three fundamental problems surface that most tools aren't built to solve.
1. Security and Compliance Risk
Most AI coding tools work by sending your code to a third-party model running on shared infrastructure. For a startup building a consumer app, that's an acceptable tradeoff. For a bank, a healthcare provider, or any team handling sensitive IP, it's a non-starter. Security teams can't approve tools that allow proprietary code, customer data, or business logic to leave the controlled environment, and most popular AI coding tools offer no verifiable guarantee that they won't.
2. Context Fragmentation
Enterprise codebases are large, interconnected, and constantly changing. The problem most teams run into is that AI tools lose context the moment you switch between them. You explain the architecture in one tool, generate code in another, run tests in a third, and by the time something breaks in CI, the AI has no memory of any of it. Every handoff means re-explaining, re-prompting, and manually bridging the gaps, which erodes most of the productivity gains the tool was supposed to deliver.
3. No Auditability
In regulated environments, it's not enough for the code to be correct; you need to be able to prove how it was produced. Who made the change? What did the AI do? Was the execution environment secure? Most AI coding tools produce outputs with no verifiable audit trail. There's no cryptographic record of what ran, where it ran, or whether the environment was tampered with. For teams subject to SOC 2, HIPAA, or financial compliance requirements, that's a dealbreaker.
These three gaps, security, context, and auditability, are exactly what the next generation of autonomous development tools is trying to close. ORGN, Devin, and Coder each take a different approach to solving them.
Three Tools Redefining Autonomous Development: ORGN, Devin, and Coder
Autonomous development tools have moved well beyond simple code completion. The three tools covered in this article, ORGN, Devin, and Coder, each represent a distinct philosophy on what an AI-powered development environment should look like, who it's built for, and what problems it prioritizes solving.
ORGN (Origin CDE) is built around one core premise: your code should never have to leave a secure, verifiable environment to benefit from AI. It targets regulated industries where compliance and auditability are non-negotiable, and its entire architecture is designed around that constraint, from hardware-level security via Intel TDX and cryptographic attestation through the OLLM gateway to full traceability on every agent action.
Devin, built by Cognition Labs, takes the opposite approach to friction. It's designed to be immediately useful, connect to a GitHub repo, describe a task in plain English, and have Devin spin up a sandboxed Ubuntu environment, plan the work, execute it, and hand you a pull request. The emphasis is on speed and autonomy, making it well-suited for solo developers or small teams who want to move fast without the overhead of setup.
Coder sits at the intersection of developer tooling and enterprise infrastructure. It combines self-hosted, governed development environments with AI agent orchestration and enterprise-grade controls, agent-specific firewalls, centralized LLM governance, and full audit logging. Where ORGN prioritizes verifiable security, and Devin prioritizes speed, Coder prioritizes team-wide governance and compliance at the infrastructure level.
The table below captures how they differ at a glance before we go deeper into each one:
ORGN | Devin | Coder | |
Core focus | Verifiable security + compliance | Speed + full autonomy | Team governance + infrastructure control |
Best for | Regulated industries | Solo devs, small teams | Enterprise compliance workflows |
Security model | Intel TDX + cryptographic attestation via OLLM | VM isolation | Agent Boundaries, SSO, self-hosted infra |
Setup | Medium | Minimal | Complex |
Access | Available | Available | Available |
ORGN (Origin CDE): AI-Powered Development Without Compromising on Security

Most AI coding tools ask you to trust their infrastructure. ORGN is built around a different premise entirely: that for teams handling sensitive code, trust isn't enough. Every AI action needs to be verifiable, every execution environment needs to be provably secure, and no code should ever touch shared infrastructure that it wasn't explicitly cleared to touch.
What ORGN Is
ORGN, officially called Origin CDE (Confidential Development Environment), is a browser-based AI development environment built for anyone where code privacy, compliance, and auditability are hard requirements, from individual engineers working with sensitive IP to regulated enterprises in fintech, healthcare, and defense. It combines a full agentic coding environment with hardware-level security, meaning the AI doesn't just help you write code; it does so inside cryptographically verified, isolated execution environments, where all workspaces run in a TDX Sandbox by default.
The security layer beneath ORGN is powered by OLLM, a proprietary AI gateway that manages requests to either standard LLMs for speed or to models running in Trusted Execution Environments (TEEs) for maximum confidentiality. When a confidential compute model is selected, inference is routed through OLLM to models running inside hardware-backed enclaves. Your code, prompts, and model outputs are processed in encrypted memory that is inaccessible to the host OS, cloud provider, or ORGN itself.
Security Architecture
ORGN's security model is built on two layers working together:
Intel TDX (Trust Domain Extensions) provides CPU-level isolation, creating encrypted virtual machine domains where code executes without exposure to the host OS or other tenants
Cryptographic attestation records, generated for every OLLM-routed confidential inference session, are retrievable from the OLLM console for audit workflows, verifying enclave identity, runtime integrity, and that expected code executed inside a verified environment
This is meaningfully different from standard VM isolation. VM isolation keeps workloads separated at the software level; a misconfigured hypervisor or a compromised host can still expose what's running inside. TEE-based confidential computing enforces hardware-level isolation, so even the cloud provider running the infrastructure cannot read what's being processed.
The Eight Security Pillars
Beyond the core architecture, ORGN enforces the following specific security properties across every session:
Pillar | What it means in practice |
Selectable Model Security | Choose standard model providers for routine work or OLLM-backed confidential LLMs for sensitive inference, per workflow |
Confidential Computing | When OLLM is selected, models run on confidential computing chips inside TEEs with hardware-backed encrypted memory |
Attestation Records | Attestation records are visible within the ORGN CDE and can be inspected in greater detail in the OLLM console; generated for every OLLM-routed confidential inference session |
User-Controlled Persistence | Nothing persists unless the user chooses it. When using OLLM confidential models, no prompts, code, or outputs are stored or used to train AI models (except operational metadata such as token counts for billing) |
Isolated Execution | All worktrees run inside a TDX Sandbox with Intel TDX-encrypted CPU and memory by default |
Controlled Collaboration | Role-based access controls and team-based permissions govern workspace access; agent authority is explicitly scoped |
Multi-Layer Encryption | Encryption enforced in transit (hardened TLS), at rest (files, tasks, context, session artifacts), and in use (encrypted during confidential inference) |
How ORGN Works: The Workflow
ORGN's workflow is organized around four interconnected layers that take a project from idea to implementation inside a single secure environment:
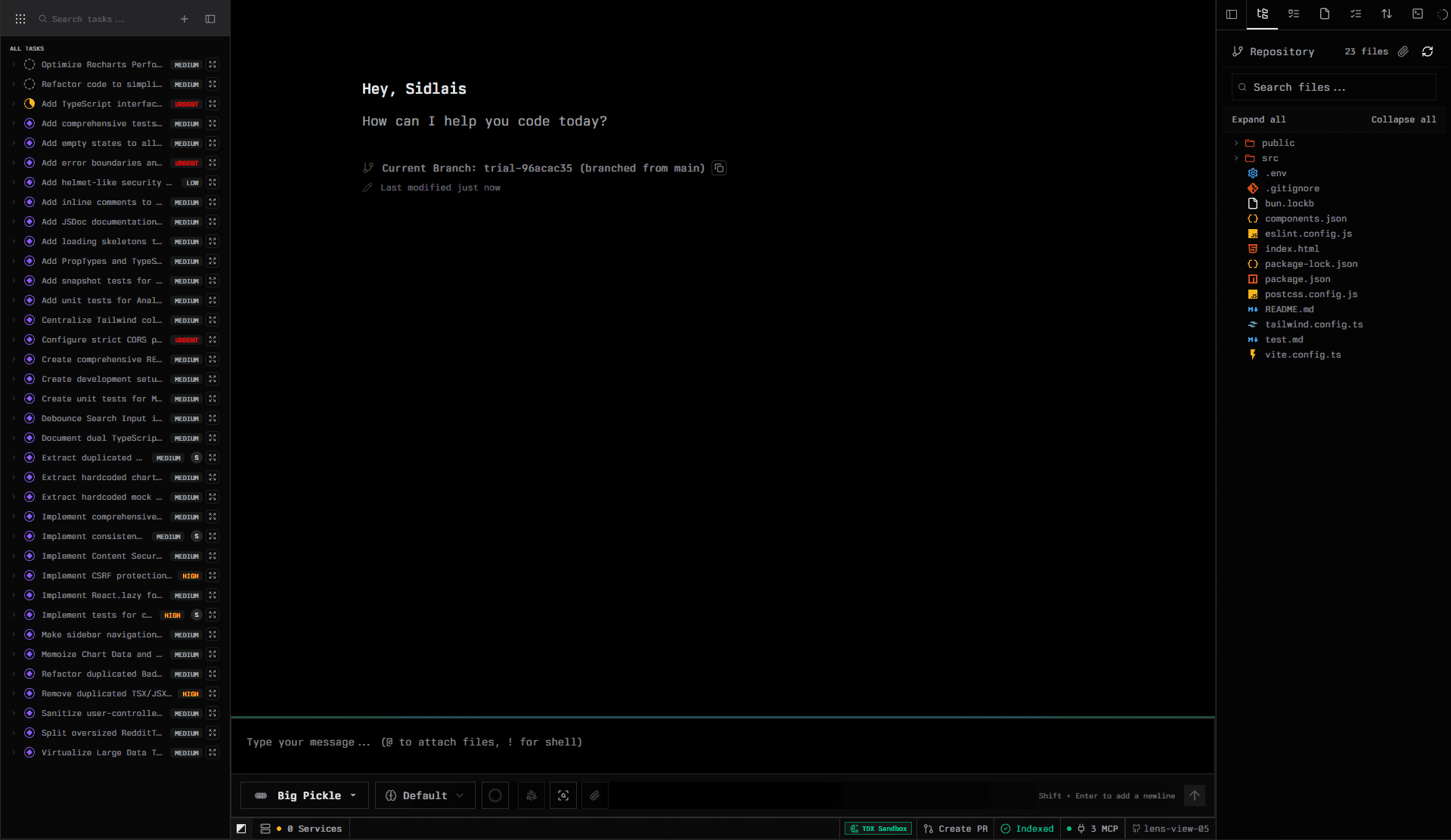
Project & Task layer: work is captured as structured tasks with priority, labels, lifecycle states (Backlog → Triage → To Do → In Progress → In Review → Completed), and assignees. Tasks can be created manually or generated by AI from repository analysis. Views are split by role: PM, Dev, QA, and SecOps, so the right work is visible to the right people.
Features layer: before any code is written, the Features workspace turns high-level ideas into structured specifications. Three modes are available: Feature Ideation (user stories, acceptance criteria, edge cases), PRD Creator (formal product requirements), and Tasks Planning (implementation-ready task breakdowns). Specifications are saved to project context and can be converted directly into tasks.
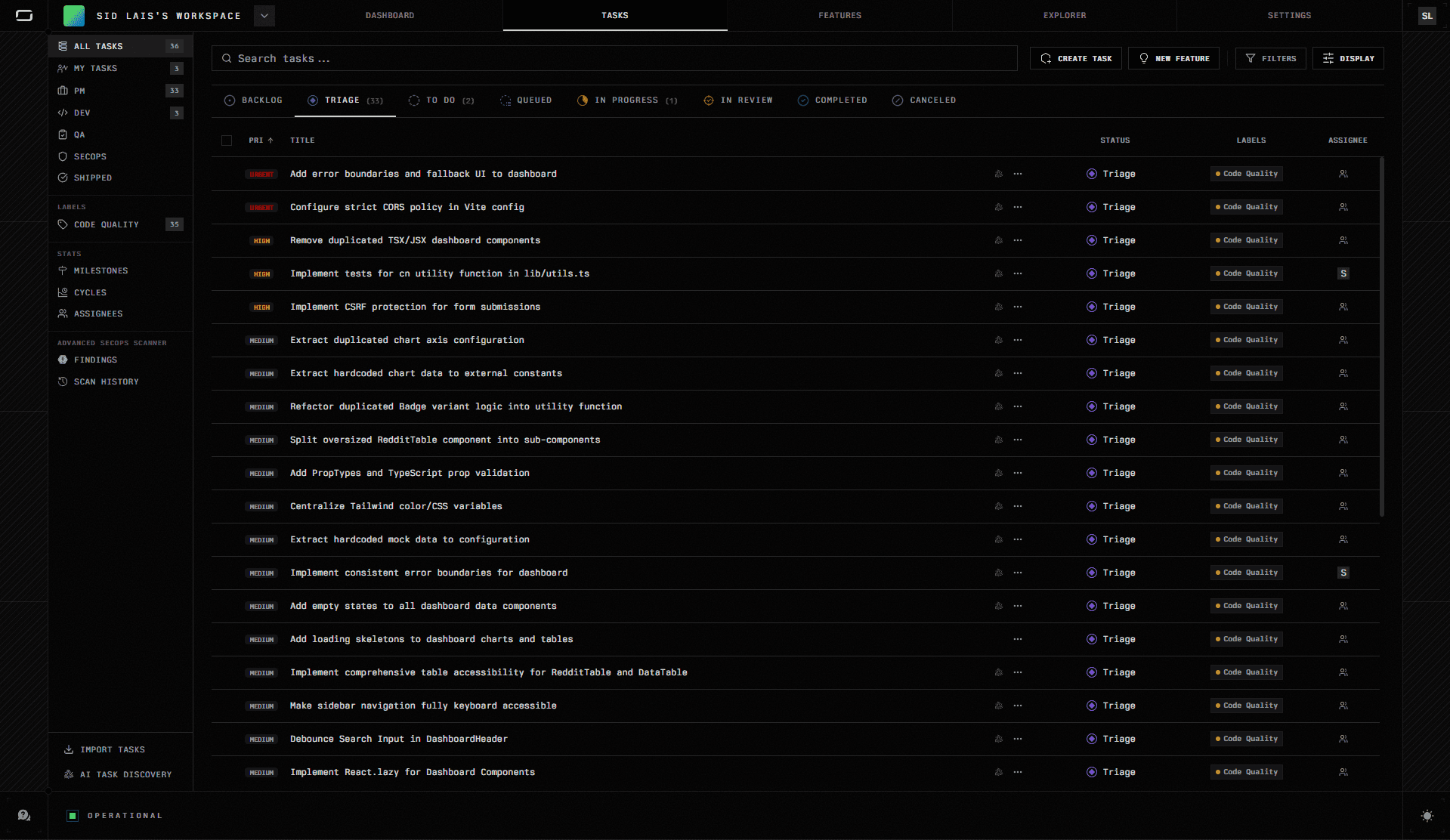
Workspace & Trial layer: each task is executed inside a Trial: an isolated, branch-based execution environment where the agent reads files, writes and modifies code, runs terminal commands, and prepares pull requests. Multiple trials can run for the same task, allowing different approaches to be explored and compared without losing earlier work. An adjustable effort level (Default, High, Max) controls how deeply the agent reasons before acting.
Review & Audit layer: Scan & Review triggers a structured quality check of all session changes before a PR is created, covering architecture consistency, security issues, edge cases, and production readiness. Every agent action, file diff, and terminal command is traceable within the session. For confidential inference sessions, attestation records are visible directly within the ORGN CDE and can be inspected in greater detail inside the OLLM console.
Who ORGN Is Best For
ORGN is built for anyone who needs to keep their code and AI interactions genuinely private, from individual engineers working with sensitive or proprietary codebases to enterprise teams in fintech, healthcare, and defense operating under formal compliance requirements. Whether you're a solo developer who doesn't want your code processed on shared third-party infrastructure or a regulated organization that needs cryptographic proof of execution for auditors, the combination of hardware-level TEE security, user-controlled data persistence, and verifiable attestation records covers both ends of that spectrum. Teams and individuals can get started directly at orgn.com.
Devin (Cognition Labs): Autonomous Engineering From Prompt to Pull Request
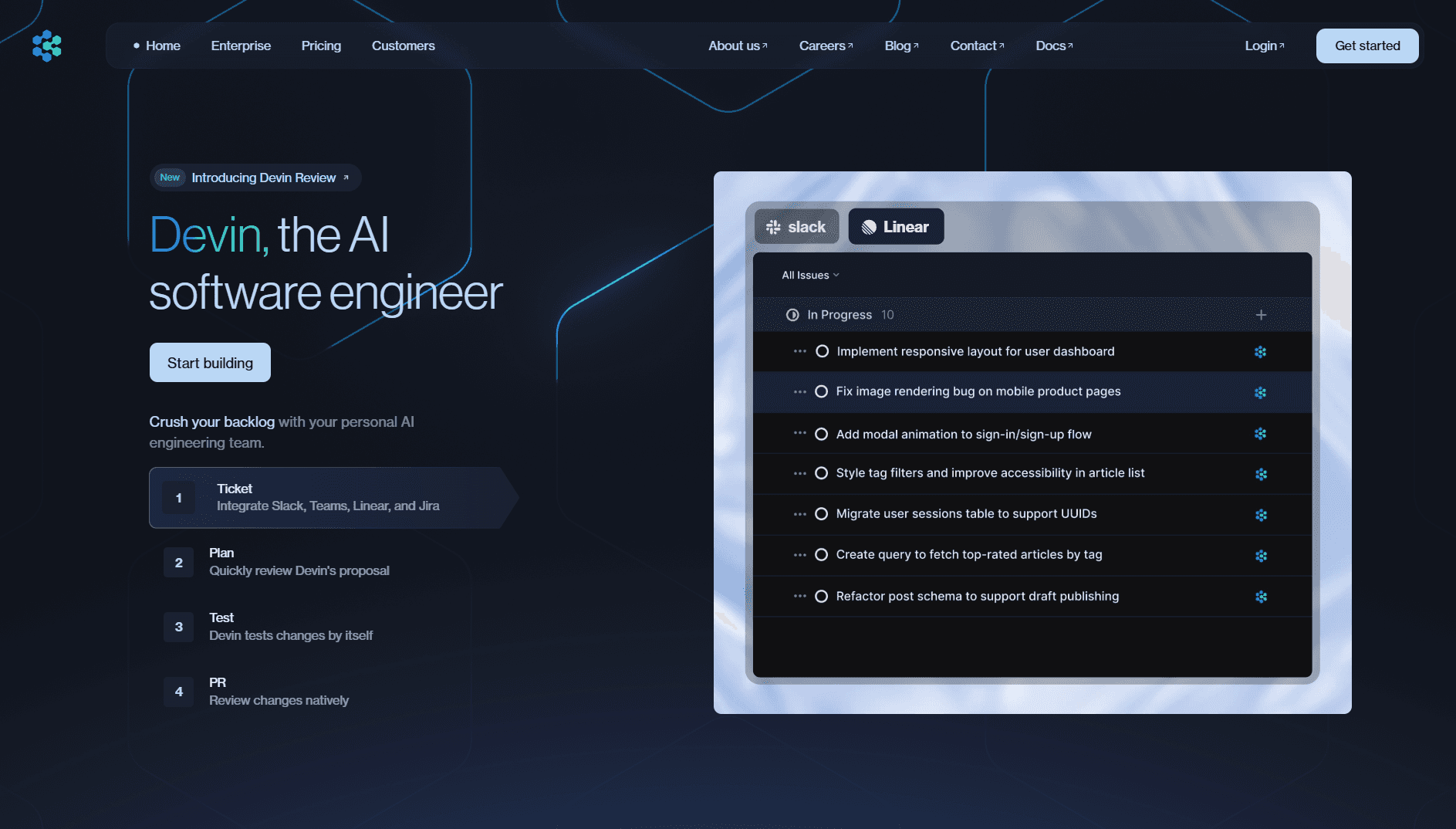
Most AI coding tools still require a developer to stay in the loop at every step, reviewing suggestions, running commands, and manually stitching the output together. Devin takes a different approach. Given a task in plain English, it plans the work, executes it inside an isolated environment, and delivers a finished pull request, with minimal human intervention in between.
What Devin Is
Devin is an autonomous AI software engineer built by Cognition Labs. It operates within a sandboxed Ubuntu virtual machine that comes preloaded with a terminal, code editor, and browser, providing a complete, self-contained environment to work in. Rather than suggesting code for a developer to accept or reject line by line, Devin handles end-to-end engineering tasks: reading the codebase, forming a plan, writing and running code, catching its own errors, and opening a review-ready pull request when the work is done.
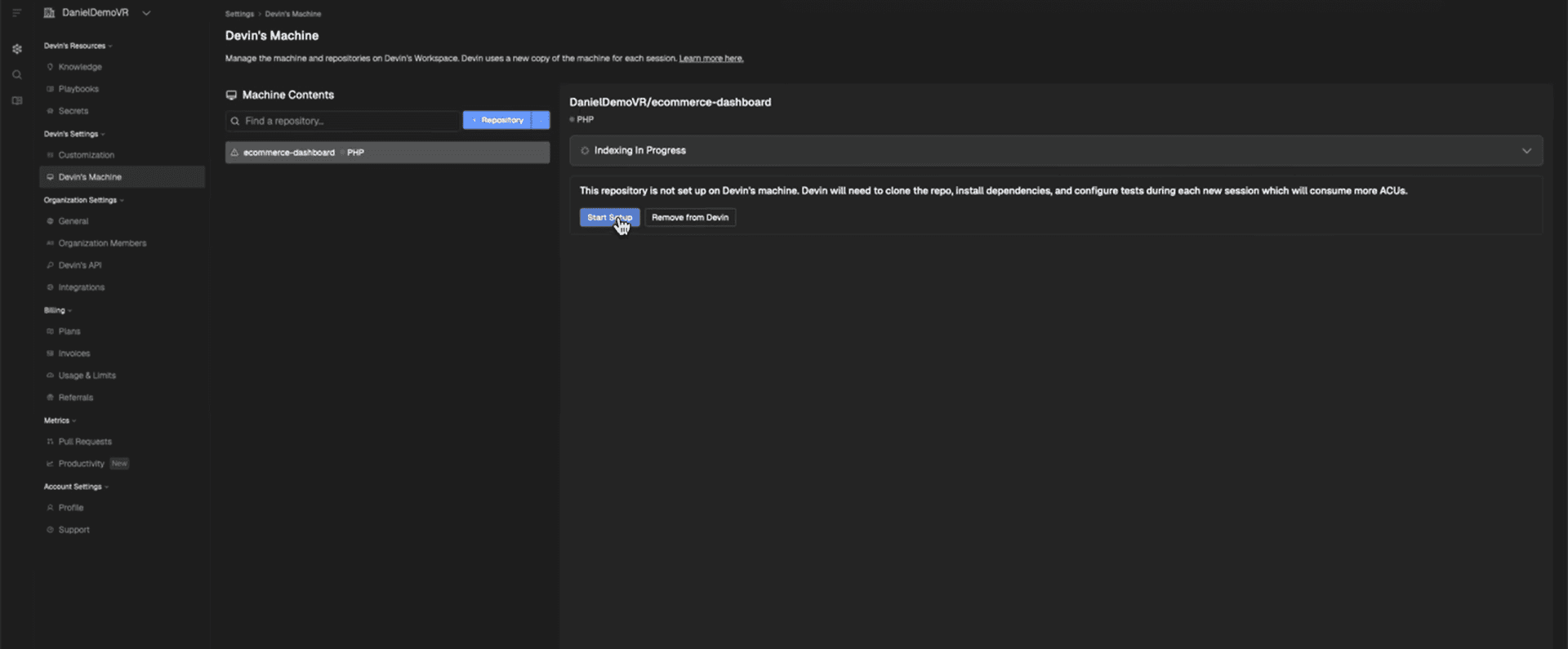
How Devin Works: The Workflow
Devin's workflow is straightforward by design. The goal is to get from a natural language task to a deployable change with as little setup friction as possible:
Connect: grant Devin access to a GitHub repository; it spins up a sandboxed Ubuntu VM, deploys the project, and opens a live workspace with terminal and editor access
Plan: describe the task in plain English, and Devin breaks it down into a step-by-step plan, including complexity assessment and a processing timeline, before executing
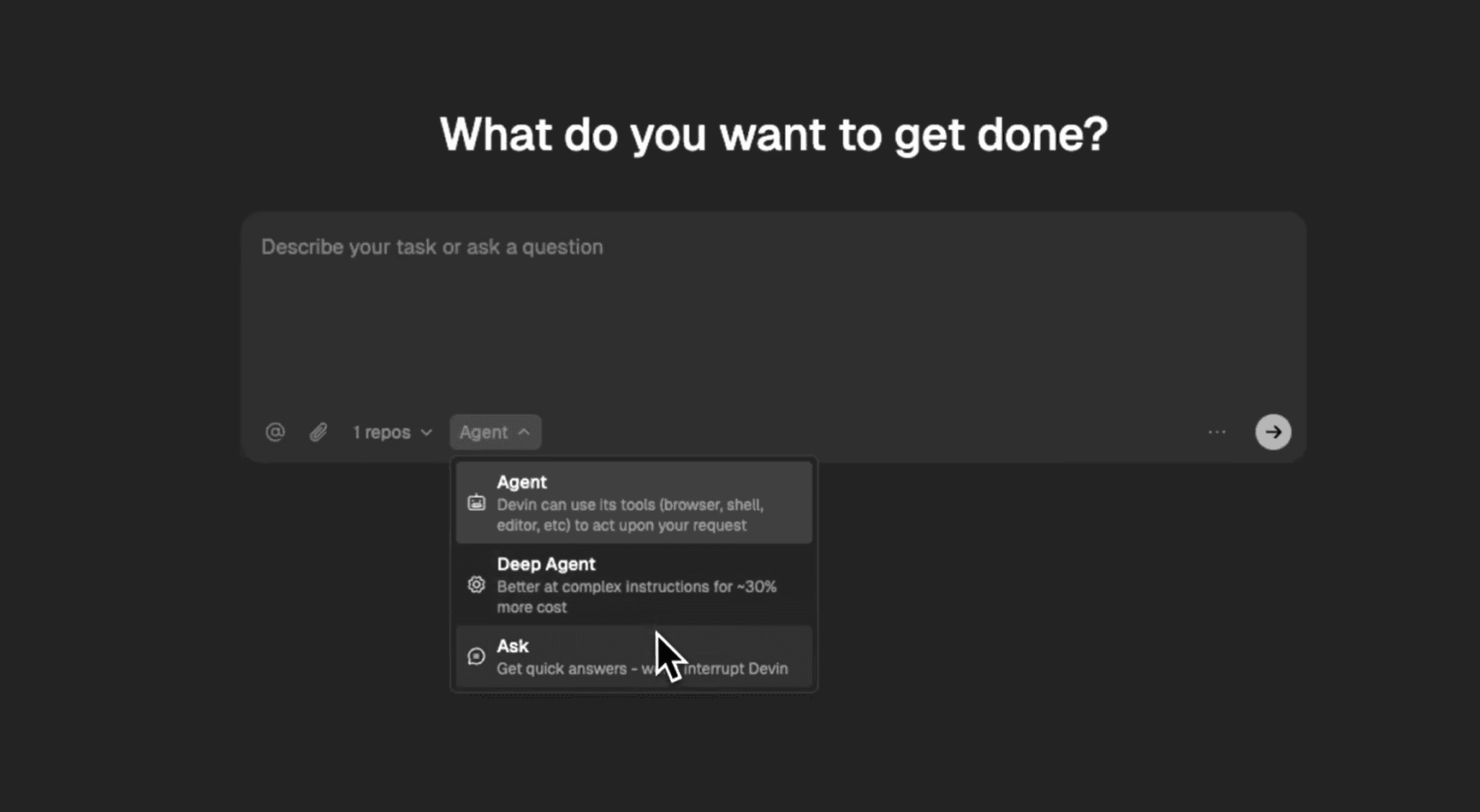
Execute: the agent works autonomously inside the VM: writing code, running commands, reading error outputs, and self-correcting until the task is complete
Collaborate: while Devin works, you can follow along in real time, leave comments, or redirect it mid-task without interrupting the execution environment
Review: Devin opens a pull request with a full summary, a checklist of changes made, and any relevant context, ready for a human to review and merge
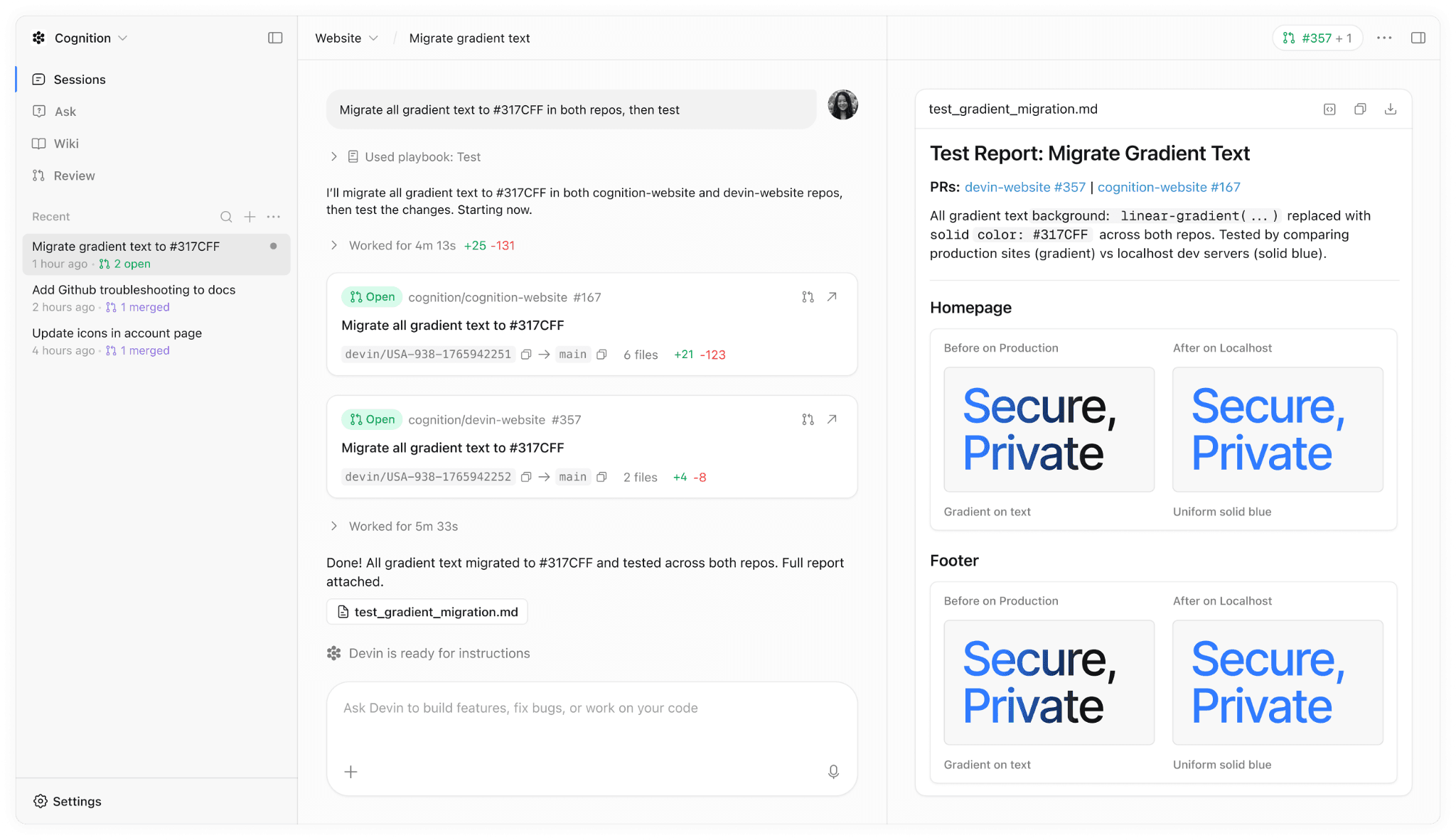
Scale: run multiple tasks simultaneously across different repos; Devin manages parallel workstreams independently without context bleed between them
Key Capabilities
Parallel task execution: Devin handles multiple complex engineering tasks at the same time across different repositories, each in its own isolated VM instance
Deep codebase search: before executing, Devin can perform a deep search across the entire repo, mapping relevant functions, dependencies, and existing patterns before writing a single line
Automated wiki generation: Devin can generate living documentation for a codebase, producing architecture diagrams, flow documentation, and API references automatically
Slack and Linear integration: tasks can be assigned to Devin directly from Slack or Linear, and it reports progress back through the same channels without requiring context switches into a separate interface
Who Devin Is Best For
Devin is best suited for solo developers or small teams seeking genuine end-to-end task automation without the overhead of complex setup. It is particularly effective for teams that need to move fast, prototyping new features, clearing a backlog of well-defined engineering tasks, or automating work that would otherwise fall to a junior engineer. Because Devin operates via VM isolation rather than hardware-level TEEs, teams in heavily regulated environments with strict data residency requirements may need to evaluate whether that security model meets their compliance needs.
Coder: Enterprise-Grade AI Development Infrastructure at Team Scale
Most AI development tools are optimized for the individual developer. Coder is built around a different unit of measure: the engineering organization. Where other tools focus on how fast a single developer can move, Coder focuses on how an entire enterprise can adopt AI-assisted development without sacrificing governance, auditability, or infrastructure control.
What Coder Is
Coder is a self-hosted AI development infrastructure platform that gives enterprises a governed environment for both human developers and AI coding agents to work side by side. Rather than offering a managed cloud service, Coder runs entirely on your own infrastructure, any cloud, Kubernetes cluster, or air-gapped on-premises environment, so code never leaves your controlled perimeter. The platform is built on three components that work together: Coder Workspaces (isolated, Terraform-provisioned environments for developers and agents), Coder Tasks (the execution layer for running and managing AI agents as governed jobs), and Coder AI Bridge (a centralized gateway that controls authentication, model access, and usage logging across every LLM provider your team uses).
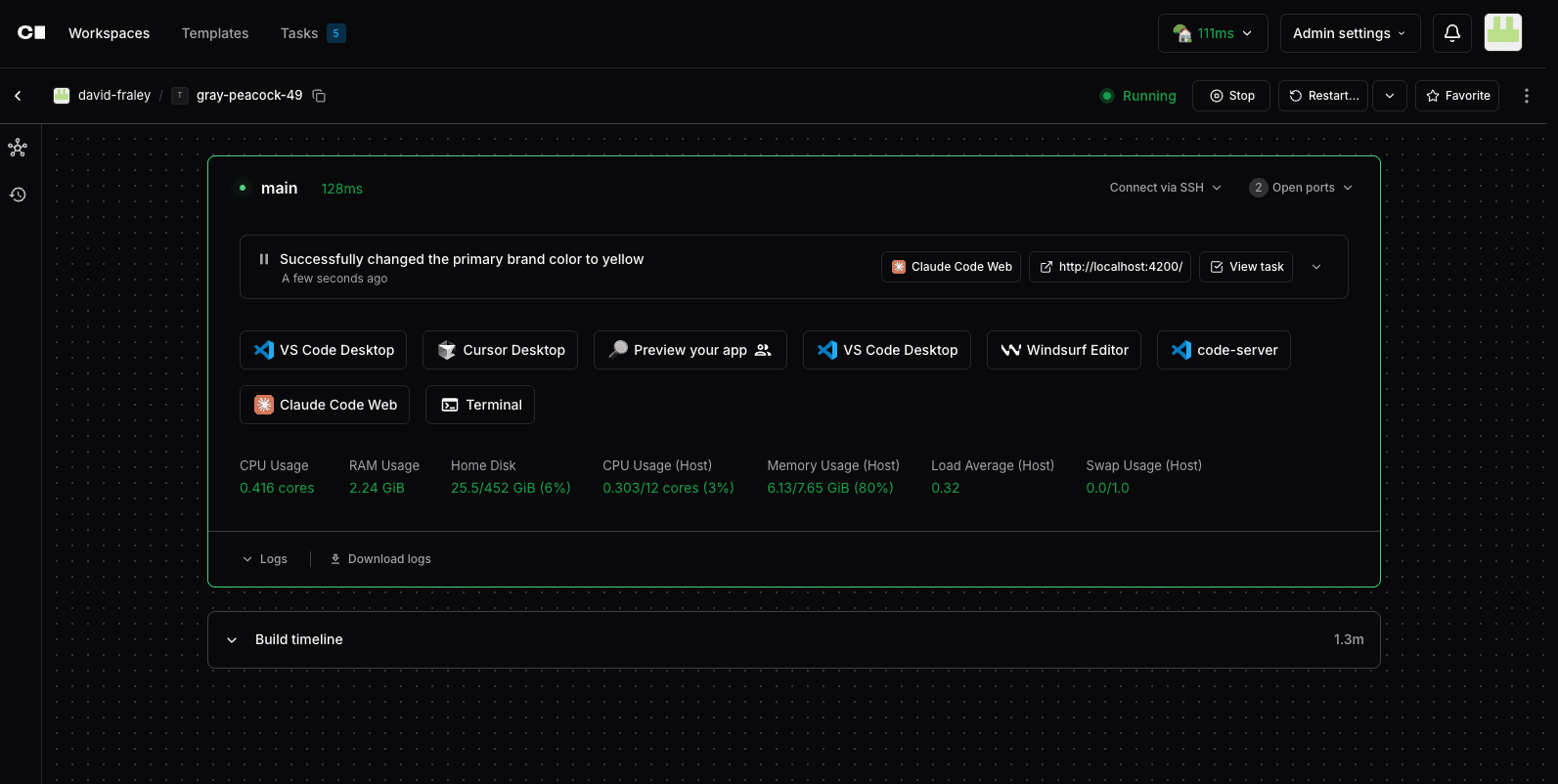
Every workspace is provisioned from a Terraform template defined by the platform team, ensuring environments are reproducible, policy-compliant, and identical across the organization. There is no "works on my machine" problem, and no developer can accidentally provision a workspace that falls outside approved security boundaries.
How Coder Works: The Workflow
Coder's workflow is built around a central platform that acts as both the developer environment and the governance layer for AI agents:
Set up: define workspace templates in Terraform, deploy Coder on your own Kubernetes or cloud infrastructure, and configure LLM providers through AI Bridge: Anthropic, OpenAI, AWS Bedrock, Google Vertex, or on-premises models
Provision: developers and agents spin up isolated workspaces in seconds from approved templates; no manual environment setup, no configuration drift
Execute: agents run inside governed workspaces via Coder Tasks, with Agent Boundaries restricting exactly which network destinations, tools, and internal systems each agent can reach
Observe: AI Bridge logs every prompt, model call, and token consumed, tagged to the individual user or agent, giving platform teams a complete audit trail in real time
Review: completed agent work surfaces as a pull request for human review; agents can be redirected before anything is merged
Scale: run parallel agent workstreams across repos and teams, each in its own isolated workspace, with centralized visibility from the platform dashboard
The Three Governance Layers
Coder gives enterprises control at every layer of the AI development stack:
Layer | How it works |
Coder Tasks | Execution engine for agent-driven automation; run long-running tasks, get notified on completion or when human input is needed |
Agent Boundaries | Agent-specific firewall; enforces explicit allow lists for network destinations, tools, and internal systems so agents only operate within approved contexts |
AI Bridge | Centralized authentication and observability gateway; every model call is tagged with user identity, token spend, and MCP tool usage — one audit trail across all providers |
Enterprise Security and Compliance
Coder’s security model is built for organizations that need controls at every layer:
Self-hosted infrastructure: deploy on any cloud, Kubernetes cluster, or fully air-gapped on-premises environment; code never touches vendor-managed shared infrastructure
Agent Boundaries: a dual-firewall model scopes each agent's network access, tool permissions, and system reach at the policy level
AI Bridge: centralizes LLM authentication, model access control, and full prompt/token logging across every provider: Anthropic, OpenAI, Bedrock, Ollama, or your own
OpenID Connect SSO: integrates with existing identity providers, including Okta, for organization-wide access control
Audit logs: every agent action, model call, and workspace event is logged and attributed to a specific user or agent, exportable for compliance reporting
Terraform-as-policy: workspace templates embed organizational security policies and tooling requirements; developers can't provision outside approved boundaries
Who Coder Is Best For
Coder is best suited for larger engineering organizations that need AI-assisted development governed at the infrastructure level, not just the application layer. It is particularly well-suited to enterprises in regulated sectors: finance, defense, and government, where the requirement is that no code or agent activity ever leave controlled infrastructure. Organizations like Palantir and Dropbox use Coder to standardize development environments across hundreds to thousands of engineers, and defense organizations, including a U.S. defense intelligence agency, have deployed it to centralize compliance in air-gapped environments. Teams should factor in that Coder requires Kubernetes operational expertise and meaningful setup investment; there is no managed cloud option, which is the point.
Choosing the Right Tool for Your Team
ORGN, Devin, and Coder are all capable autonomous development tools, but they are built for meaningfully different contexts. Picking the wrong one doesn't just mean a suboptimal experience; it means friction at exactly the points that matter most, whether that's security, setup, or team coordination. The comparison below covers the dimensions that actually determine fit.
Side-by-Side Comparison
ORGN | Devin | Coder | |
Core focus | Verifiable security + compliance | Speed + full autonomy | Team governance + infrastructure control |
Architecture | Browser-based CDE; all workspaces run inside a TDX Sandbox; confidential inference routed via OLLM | Sandboxed Ubuntu VM | Self-hosted on any cloud, Kubernetes, or air-gapped on-prem |
Security model | Hardware-level TEE attestation + cryptographic attestation records via OLLM console | VM isolation | Agent Boundaries firewall + AI Bridge governance + SSO |
Agent modes | Single agent inside the Workspace/Trial environment | Single autonomous agent | Coder Tasks (execution) + Agent Boundaries (firewall) + AI Bridge (governance) |
Context persistence | Persistent knowledge base per project across sessions | Session-based VM continuity | Workspace-scoped; ephemeral by default, persistent if configured |
Setup complexity | Low, browser-based, no local install | Low, connect GitHub and go | High: Terraform templates, Kubernetes, self-hosted deployment |
LLM flexibility | Standard or confidential-compute models via the OLLM gateway or other standard gateways | Fixed model selection | Any provider via AI Bridge: Anthropic, OpenAI, Bedrock, Ollama, on-prem |
Enterprise readiness | Yes, compliance, attestation, and user-controlled data persistence | Limited, no hardware TEEs or formal audit trails | Yes: SSO, audit logs, agent firewalling, infrastructure-level data sovereignty |
Availability | Publicly available | Publicly available | Publicly available |
Best for | Privacy-conscious developers, regulated industries: fintech, healthcare, defense | Solo devs and small teams moving fast | Large engineering teams requiring infrastructure-level agent governance |
When to Use Which Tool
The right choice comes down to three factors: your security requirements, your team size, and the amount of setup overhead you can absorb.
ORGN is the right choice when code privacy is non-negotiable, whether that's because you're a developer who won't accept third-party models processing your IP on shared infrastructure, or because your organization operates in a regulated sector and needs cryptographic proof of how code was handled. ORGN's hardware-level TEE security and verifiable attestation records are built for both.
Devin is the right choice when speed and autonomy matter more than the compliance overhead. For solo developers, early-stage teams, or anyone who needs to clear a backlog of well-scoped engineering tasks without setting up complex infrastructure, Devin gets you from a natural-language prompt to a merged PR faster than anything else.
Coder is the right choice when the challenge isn't individual developer speed; it's putting the entire engineering organization's AI usage under governance you actually control. If your security team requires that agent workloads never leave your own infrastructure, that every model call is logged and attributed, and that agent permissions are enforced at the network level rather than the application level, Coder is built for exactly that.
The Real Risks of AI-Assisted Development and How to Manage Them
AI development tools are genuinely powerful, but adopting them without understanding their failure modes leads teams to security incidents, compliance violations, and codebases full of plausible-looking bugs. The risks below are not theoretical; they are the ones that engineering teams actually encounter as they move AI from experimentation to production workflows.
Hallucinated Code
LLMs generate code that looks correct before it is correct. A model can produce a syntactically valid, logically coherent function that silently fails on edge cases, uses a deprecated API, or introduces a subtle security vulnerability, and it will do so confidently, without flagging any uncertainty. The mitigation isn't to use AI less; it's to treat every AI-generated output as unreviewed code. That means enforcing test coverage requirements on AI-generated changes, running static analysis, and keeping humans in the review loop rather than auto-merging agent-produced PRs.
Data Exposure
Most AI coding tools process your code on shared third-party infrastructure. For many teams, that's acceptable, but for teams handling sensitive IP, customer data, or regulated information, every prompt sent to a standard LLM endpoint is a potential data exposure event. The mitigation is either to enforce strict policies on what can be sent to AI tools or to move to tools that process code in verified, isolated environments where the infrastructure provider itself cannot read what's being processed.
Over-Reliance Without Review
The productivity gains from autonomous agents are real, but they create a new risk: developers who stop reading the code the AI produces. When agents handle entire tasks end-to-end and open PRs directly, there is a temptation to treat a green CI pipeline as sufficient review. It isn't. AI agents can produce code that passes all existing tests while still being architecturally wrong, introducing tech debt, or missing requirements that weren't explicitly stated. Keeping a genuine human review step, not a rubber stamp, is non-negotiable.
Auditability Gaps in Regulated Environments
For teams subject to SOC 2, HIPAA, PCI-DSS, or financial services regulations, the question isn't just whether the code is correct; it's whether you can prove how it was produced, in what environment, and by whom. Most AI coding tools produce no verifiable record of this. The mitigation is to either use tools that generate cryptographic audit trails by design or to build your own logging layer that captures AI interactions, model versions, and execution contexts before they become a compliance liability.
Supply Chain Risk
AI agents with access to your repositories, CI/CD pipelines, and deployment infrastructure significantly expand your attack surface. A compromised agent, a misconfigured permission scope, or a prompt-injection attack, in which malicious content in a file or issue tricks an agent into executing unintended actions, can have consequences that propagate across an entire codebase. The mitigation is to apply the same least-privilege principles to AI agents that you would to any third-party service: scope permissions tightly, audit what agents have access to, and never give an agent write access to production infrastructure without an explicit human approval step.
Conclusion: Getting Started With AI Software Development
AI software development has moved far beyond autocomplete. The tools available today, ORGN, Devin, and Coder, can handle entire engineering workflows autonomously, from reading a codebase and planning a task to writing code, running tests, and opening a pull request. Each one takes a distinct approach: ORGN prioritizes verifiable security for privacy-conscious developers and regulated teams alike, Devin prioritizes speed and autonomy for individuals and small teams, and Coder prioritizes governance and infrastructure control at the organizational level. The right choice comes down to where your team sits on the spectrum of security requirements, team size, and setup tolerance.
To move forward, start by identifying the constraint that matters most to your team right now. If it's code privacy, compliance, or working with sensitive codebases without relying on trust, try orgn.com. If it's shipping faster with minimal setup, get started with Devin by connecting a GitHub repo and running your first autonomous task. If it's governing AI development across an entire engineering organization, start by deploying Coder on a single team's infrastructure, define a workspace template for one repository, and expand from there. The most important step is to start with a well-scoped task, keep humans in the review loop, and build trust in the tooling incrementally.
Frequently Asked Questions
What is the difference between TEE-based confidential computing and standard VM isolation in AI development tools?
VM isolation separates workloads at the software level; a compromised hypervisor or misconfigured host can still expose what's running inside. TEE-based confidential computing, which ORGN uses via Intel TDX, enforces hardware-level isolation. Code, prompts, and model outputs are processed inside an encrypted memory that is inaccessible to the host OS, the cloud provider, and other tenants, regardless of what happens at the software layer above it.
How do autonomous AI coding agents handle security in regulated industries like fintech and healthcare?
Most autonomous agents operate via VM or process isolation, which keeps workloads separated but offers no cryptographic proof of what happened during execution. For regulated industries, that's the core gap: you can't demonstrate to an auditor that code was processed in a verified, tamper-free environment based solely on software-level guarantees. Teams subject to SOC 2, HIPAA, or PCI-DSS need tools that produce exportable attestation records, not just isolated sandboxes.
What is prompt injection, and why does it matter for AI software development agents?
Prompt injection is an attack where malicious content embedded in a file, issue, or external input tricks an AI agent into executing unintended actions. In an autonomous development context, this is particularly dangerous because agents have write access to codebases, can run shell commands, and interact with CI/CD pipelines. Mitigating it requires tightly scoping agent permissions, auditing which inputs agents can read, and never granting write access to production infrastructure without an explicit human approval gate.
How does ORGN's OLLM gateway execute requests in confidential compute environments?
OLLM is ORGN's proprietary unified AI gateway that sits between your development environment and the underlying models. On a per-request basis, it executes requests in standard LLMs for everyday work or to models running inside TEEs when confidentiality is required. When a TEE-enabled model is selected, the entire inference pipeline, input, model execution, and output, runs inside a hardware-attested environment backed by Intel TDX. Each session produces cryptographic attestation records that link every response back to the verified execution context that produced it.
How does ORGN handle data persistence, and what does that mean for developers working with sensitive code?
ORGN is built on the principle of minimal persistence: nothing is retained unless the user actively chooses to retain it. Worktree data follows a defined lifecycle before teardown, and users can trigger immediate teardown at any time by archiving and deleting their worktree. Throughout that lifecycle, all data sits inside a TDX-encrypted sandbox, meaning even retained data is encrypted at the hardware level and inaccessible to anyone other than the user. For developers using OLLM confidential models specifically, the guarantee goes further: no prompts, code, or outputs are stored or used to train AI models at any point, except for operational metadata such as token counts needed for billing. For individual developers working with proprietary code, this means your work stays yours. For compliance teams, it means the attack surface is structurally limited rather than dependent on policy promises.